

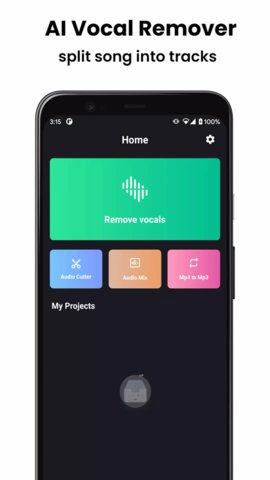
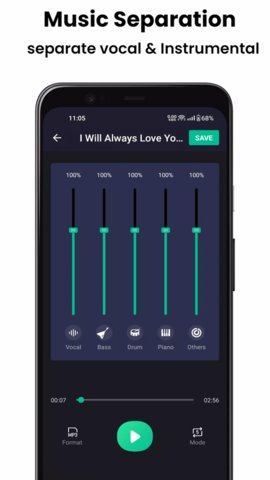
Vocalremover是一款基于人工智能技术的专业音频处理工具,其核心功能在于运用先进的深度学习算法,对输入的歌曲音频文件进行高精度的源分离,从而将人声(Vocal)与伴奏(Instrumental)分离开来。软件不仅能够生成高质量的卡拉OK伴奏带,满足个人娱乐与演唱需求,还能提取出纯净的人声音轨,为音乐制作人、内容创作者(如视频博主、混音师)进行二次创作、采样、混音或声乐分析提供强大的素材支持。其处理过程高效快捷,对用户的技术背景要求极低,使得从普通音乐爱好者到专业音频工作者都能便捷地利用其核心能力,显著提升了音频编辑与创作的效率与可能性。
Vocalremover软件特色介绍
Vocalremover的核心竞争力植根于其技术架构与用户体验设计的深度结合,以下四项特色是其对用户产生关键助益的体现:
算法模型的先进性与专业性。软件并非采用通用的简单滤波技术,而是基于改进的深度神经网络模型进行构建与训练。此类模型通过对海量已标注(人声与伴奏分离)的音乐数据进行学习,能够精准识别并建模人声与各类乐器声音在频域和时域上的复杂特征与关联。在处理过程中,软件能更有效地区分主唱人声、和声与不同乐器的声音成分,实现更为干净、残留杂音更少的分离效果,尤其在处理人声与伴奏交织紧密的现代流行音乐时表现突出。
高效的处理引擎与广泛的格式兼容性。软件后台部署了优化的计算引擎,能够充分利用计算资源,使得常规长度的歌曲在云端上传后,能在短时间内完成分析、分离与渲染全过程,极大地减少了用户的等待时间。软件支持包括MP3、WAV、FLAC、OGG、M4A在内的多种主流无损及有损音频格式作为输入,输出文件同样提供高质量的可选格式(如WAV),确保了从源文件到成品文件工作流的顺畅,避免了因格式转换导致的质量损失或额外步骤。
第三,面向工作流的实用功能设计。除了核心的分离功能,提供了批量处理能力,允许用户一次性上传多个音频文件进行队列处理,这对于需要处理整张专辑或大量素材的用户而言,是显著的效率提升工具。软件针对不同音乐流派(如流行、摇滚、古典、电子)可能存在的混音特点,内置了相应的优化处理方案,用户可根据曲风选择对应模式,以获得更贴合该音乐类型特性的分离结果,这体现了其功能设计的专业性与细致度。
第四,灵活的服务模式与可访问性。软件提供了基于Web的在线版本以及可下载的桌面客户端。在线版本无需安装,通过浏览器即可随时随地使用,便捷性极高;而桌面客户端则更适合需要离线操作、处理大文件或追求更稳定连接环境的专业用户。这种双模式策略覆盖了更广泛的用户场景。更重要的是,其核心的人声/伴奏分离服务提供了免费的额度,显著降低了用户体验先进AI音频处理技术的门槛,促进了工具的普及。
Vocalremover软件功能
Vocalremover的具体功能围绕音频源分离这一核心,解决用户在音乐制作、内容创作及娱乐中的多种特定痛点:
1. 高精度人声与伴奏分离:这是软件的基础与核心功能。它直接解决了音乐爱好者无法获得高质量纯伴奏进行演唱练习或表演的痛点,也解决了创作者需要从现有作品中提取人声样本进行再创作(如制作Remix、Mashup)时,面临分离不净、音质损伤严重的问题。通过AI深度分离,得到的伴奏轨人声残留极少,人声轨的乐器干扰也得到最大程度抑制。
2. 多文件批量处理:针对音乐教师、播客制作人或需要处理大量历史录音的用户,手动单曲处理效率低下。批量处理功能允许用户上传一个包含多个音频文件的文件夹或列表,系统自动按序处理并打包输出结果,极大地节省了用户重复操作(上传、等待、下载)的时间与精力,实现了自动化流水线作业。
3. 分轨独立预览与高质量导出:分离完成后,软件界面会并排显示生成的人声音频波形与伴奏音频波形,并提供独立的播放控制器。在下载前实时试听、对比分离效果,确保结果符合预期,避免了因效果不佳导致的重复处理和等待。确认满意后,用户可分别下载两个音轨,导出文件支持高比特率的WAV等格式,保证了后续在专业数字音频工作站(DAW)中进行编辑时拥有足够的音频质量。
4. 音乐风格自适应处理选项:不同音乐风格的混音平衡和声场设计差异巨大。古典音乐可能拥有庞大的交响乐团声场,而电子音乐则强调密集的合成器铺底。软件提供风格化处理选项,实质上是调用针对特定数据集优化过的算法参数。用户选择相应风格后,软件能更好地处理该风格中常见的声像定位、频率分布特点,从而提升分离的准确度,解决了一刀切算法在某些曲风上效果不佳的痛点。
5. 纯人声提取与纯伴奏生成:此功能是核心分离的两种直接应用输出。纯人声提取功能为语音分析、声乐技巧学习、或特定需要仅保留人声的影视配乐场景提供了可能。纯伴奏生成则直接服务于卡拉OK、街头表演、视频背景音乐替换等广泛应用场景,解决了用户寻找官方伴奏困难或官方伴奏版本不符需求的问题。
未来前景
Vocalremover所代表的AI音频源分离技术,其发展潜力远不止于当前的人声与伴奏分离。随着深度学习模型,特别是生成式对抗网络(GAN)、扩散模型(Diffusion Models)以及更先进的时频域变换网络的发展,未来的分离精度将逼近甚至达到无损级别,能够处理更加复杂、混音极其密集的现代音乐。技术演进方向可能包括:多音轨分离(不仅分离人声和伴奏,还能进一步分离出鼓组、贝斯、钢琴、吉他等单个乐器轨),实现真正的音乐解混音;对历史单声道录音进行智能声场扩展与音源分离,为老歌修复和重制开辟新途径;实时分离技术的成熟,将可能应用于现场演出、直播K歌等场景,实现实时消音或人声增强。
该技术与语音识别、音乐信息检索(MIR)、自动编曲等领域的结合将更加紧密。分离出的干净人声可以用于更准确的歌词识别与翻译,或用于训练个性化语音合成模型;分离出的伴奏则可进行自动和弦分析、曲式结构识别,辅助音乐教育。从更广阔的视角看,此类技术是构建未来智能音乐创作生态系统的基础模块之一,它将极大地降低音乐制作与改编的技术门槛,激发全民创作热情,并可能催生新的艺术形式和内容生产模式。对于用户而言,掌握并善用此类工具,意味着在未来的数字内容创作领域占据了重要的技术先机。
值得注意的是,随着技术的普及,相关的版权与伦理问题也将愈发重要。用户在使用工具进行作品再创作时,必须充分尊重原作品著作权,遵守相关法律法规。软件提供商亦需在技术发展的积极建立并引导用户形成合规使用的社区规范,确保技术创新在健康的生态中持续发展,服务于更广泛的艺术创作与文化繁荣。








